


💥What is kubernetes?🤔
Kubernetes is an open-source container orchestration tool system for automating software deployment, scaling, and management. “Kubernetes” is a Greek word, which means helmsman or pilot. “K8s” is an abbreviation derived by replacing the eight letters “ubernete” with “8”.It is used for automating deployment, scaling, and management of containerized applications. Google originally designed Kubernetes, but the Cloud Native Computing Foundation now maintains the project.
💥What Problems kubernetes solved?🤔
The rise of microservices cause increase the use of the container because container offer the perfect host for small independent application like microservices. So the rise of microservices and the container it is difficult or nearly impossible to manage more and more container across multiple environment using script and self made tool can be complex and here’s where kubernetes comes in. Those hundreds or may be thousands of containers can be managed by kubernetes.
Let's assume an application. It has multiple services running inside containers. Now, each container have to be scaled as per requirements, the code has to be managed.
As containers are scalable so, we can scale it up to a definite number. But this is going to take lots of manual effort. In real world scenarios where you want to scale it up to like 50-100 containers then in that case what happens is that after you scale up these containers manually then you have to manage containers means you have to check whether all are working or not, they are active or not, they are talking to each other or not. So. it's a big task to handle so many containers manually. So, to scale up these containers, we need something so that you don't have to worry about the track of these containers. Here, the Orchestration comes into the picture.
💥Features
High availability or no down time :- The applications has no downtime so that it can always accessible by user.
Scalability or high performance:- We can scable the application even if there is more load.
Diaster recovery-Backup and Restore:- Let’s assume the worst case scenario like infrastructure as a problem like data is lost then the it have some mechanism to pickup the data and restore it to the latest state so the application does not loose any data.
Storage orchestration:- Automatically mount the storage system of your choice, whether from local storage, a public cloud provider such as GCP or AWS, or a network storage system such as NFS, iSCSI, Gluster, etc.
💥Challenges in Kubernetes
Security
In Kubernetes security is one of the greatest challenges because of its complexity and vulnerability. If not properly monitored, it can obstruct identifying vulnerabilities.
Tesla cryptojacking attack is one of the best examples of a Kubernetes break-in, where the hackers infiltrated Tesla’s Kubernetes admin console. This led to the mining of cryptocurrencies through Tesla's cloud resources on Amazon Web Services (AWS).
Networking
The reason is mainly, that the traditional networking approaches don’t work well with Kubernetes. The larger the scale of Kubernetes deployment, the more challenges will be faced. Some of the most common network Kubernetes challenge faced by users are
● Complexity challenge:- Mainly due to the deployment of Kubernetes in more than one cloud infrastructure like private, public, and hybrid. Each cloud infra has its own policy which makes Kubernetes complex across multiple infrastructures
● Addressing challenge:- That are typically faced are that of static IP addresses and ports getting difficult to be used in Kubernetes for communication because pods can use an infinite number of IP addresses.
● Multi-tenancy challenge:- This challenge usually arrives at a situation where one Kubernetes environment is shared among multiple workloads. Obviously when two or more are sharing one thing there arises these basic challenges like resource sharing and security. So, there is a high chance if workloads are not properly isolated security breach in one workload will affect the other workloads in the same environment.
This problem solve with service mesh. A service mesh is an infrastructure layer inserted in an app that handles network-based intercommunication via APIs. It also allows developers to be stress-free with networking and deployment.
Storage
Storage is an issue with Kubernetes for larger organizations, especially organizations with on-premises servers. One of the reasons is that they manage their entire storage infrastructure without relying on cloud resources. This can lead to vulnerabilities and memory crises.
Interoperability
Interoperability means exchange messages or information in a way that both can understand
As with networking, interoperability can be a significant Kubernetes issue. When enabling interoperable cloud-native apps on Kubernetes, communication between the apps can be a bit tricky. It also affects the deployment of clusters, as the app instances it contains may have problems executing on individual nodes in the cluster.
💥Architecture
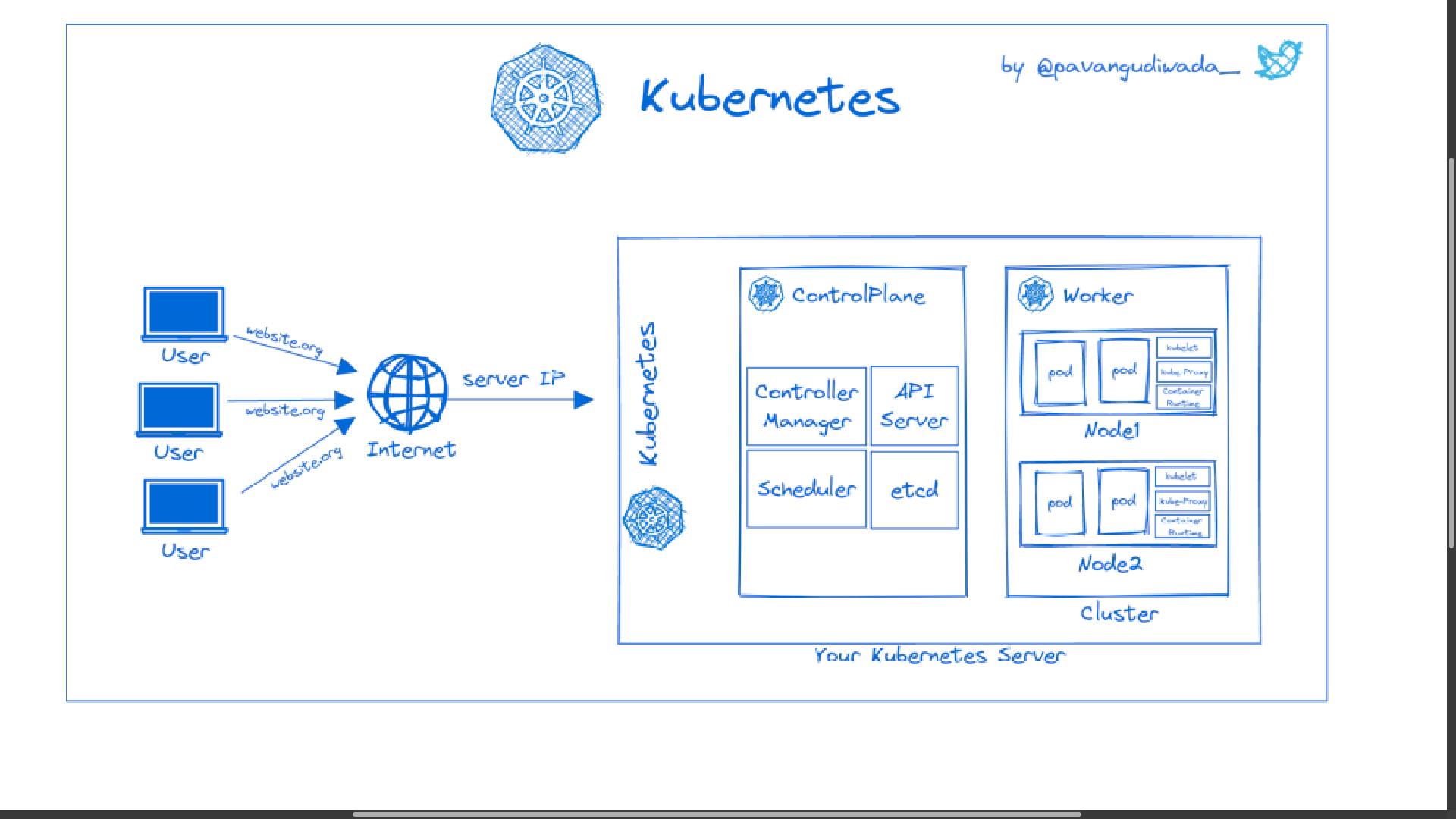
- Kubernetes Architecture consists of at least one main (control) plane or master node, and one or more worker machines or nodes.Where each nodes has a Kublet(Kublet is a Kubernetes process that make it possible to a cluster to talk to each other and execute some task on that node like running application process) process running on it.
- Worker node are where our application are running on it.
- Each worker node has container of different application deployed on it. Depending on the load distributed we have different number of docker container running on worker node.
💥What’ s running on master node?
Master node actually runs several Kubernetes process that are necessary to run and manage the cluster properties. If a worker node fails, the master node moves the load to another healthy worker node. Master node is responsible for scheduling, provisioning, controlling and exposing API to the clients. It coordinates activities inside the cluster and communicates with worker nodes to keep Kubernetes and applications running.
💥Component of the Master node
✨ Api Server
- Api server is also a container which is an entry point to a kubernetes cluster. CRUD operations for servers go through the API. It is the front end for the Kubernetes control plane.
- Api server configures the Api objects such as pods, services, replication controllers and deployments.
- It exposes API for almost every operation. How to interact with this API? Using a tool called kubectl aka kubecontrol.
- It talks to the API server to perform any operations that we issue from cmd. In most cases, the master node does not contain containers. It just manages worker nodes, and also makes sure that the cluster of worker nodes are running.
✨ Scheduler
- Scheduler is responsible for scheduling containers on different node based on the workload and available server resources on each node.
- It schedules pods to worker nodes.
✨ Control Manger
Each controller is a separate process, but to reduce complexity, they are all compiled into a single binary and run in a single process.
- Node controller: Responsible for noticing and responding when nodes go down.
- Job controller: Watches for Job objects that represent one-off tasks, - then creates Pods to run those tasks to completion.
- Endpoints controller: Populates the Endpoints object (that is, joins Services & Pods).
- Service Account & Token controllers: These controllers are responsible for the overall health of the entire cluster. It ensures that nodes are up and running all the time as well as the correct number of Pods are running as mentioned in the spec file.
✨ Etcd
- Most important component of the whole cluster. It’s a key value storage which holds the current state of kubernetes cluster, so it has all the configuration data inside and all the status data of each node and each container inside of that node.
- Backup and restore are made through Etcd snapshots because we can recover the whole cluster state using that etcd snapshots.
💥Worker node
- The worker node is known as data plane or compute node.
- A Kubernetes cluster needs at least one worker node, but normally has many.
- The worker node(s) host the pods that are the components of the application workload.
- Cluster can be scaled up and down by adding and removing nodes.
Component of the Worker node
🌟 Kubelet
- Primary Node agent that runs on each worker node inside the cluster. - - The primary objective is that it looks at the pod spec that was submitted to the API server on the Kubernetes master and ensures that containers described in that pod spec are running and healthy.
- Incase Kubelet notices any issues with the pods running on the worker nodes, it tries to restart the Pod on the same node.
- Gets instructions from master and reports back to Masters.
🌟 Kube-Proxy
- Responsible for maintaining the entire network configuration. It maintains the distributed network across all the nodes, across all the pods, and all containers.
The kube-proxy will feed its information about what pods are on this node to iptables.
iptables is a firewall in Linux and can route traffic.
It ensures each pod gets a unique IP address and makes possible that all containers in a pod share a single IP.
It maintains network rules on nodes. These network rules allow network communication to Pods from inside or outside the cluster.
🌟Pods
- A scheduling unit in Kubernetes. Pods are the smallest deployable unit in a Kubernetes cluster.
- Like a virtual machine in the virtualization world. In the Kubernetes world, we have a Pod. Each Pod consists of one or more containers. - --- With the help of Pods, we can deploy multiple dependent containers together. Pod acts as a Wrapper around these containers. We interact and manage containers through Pods.
🌟 Containers
- Containers are Runtime Environments for containerized applications. We run container applications inside the containers.
- These containers reside inside Pods. Containers are designed to run Micro-services.
- To run the containers, each worker node has a container runtime engine.
- Kubernetes supports several container runtimes like Docker, contained, CRI-O.
More about Pods
Every node inside a Kubernetes cluster has its unique IP address known as Node IP Address. In Kubernetes, there is an additional IP Address called Pod IP address. So once we deploy a Pod on the worker node, it will get it’s own IP Address. Containers in pods communicate with the outside world by network namespace. All the containers inside a pod operate within that same network namespace as the pod. Means all the containers in a pod will have the same IP Address as their worker node. There is a unique way to identify each container. It can be done by using ports. Note: Containers within the same pod, not only just share the same IP Address, but will also share the access to the same volumes, c-group limits, and even same IPC names.
💥Pod Networking
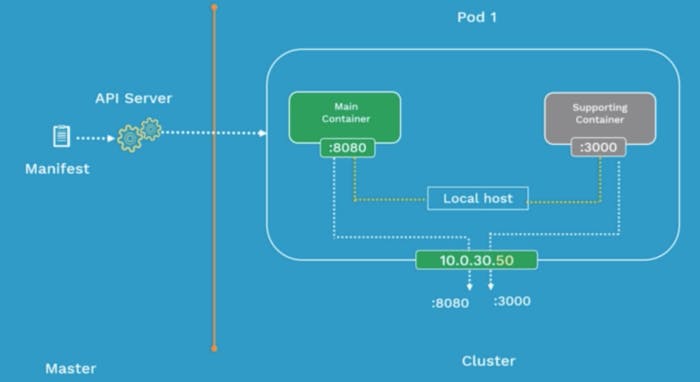
How do Pods communicate with one another?🤔
- Inter-Pod communication: All the Pod IP addresses are fully routable on the Pod Network inside the Kubernetes cluster.
In Kubernetes, each Pod has its own IP address. At a very primitive level, Pods can communicate with each other using their IP address. This means that whenever you need to address another Pod, you can do it directly, using its IP address. This gives Pods similar characteristics to virtual machines (VMs), where each Pod has its own IP address, can expose ports, and address other VMs on the network by IP address and port.
How do containers communicate in the same pod?🤔
- Intra-Pod Communication: Containers use shared Local Host interface. All the containers can communicate with each other’s port on local host.
Multiple containers in the same Pod share the same IP address. They can communicate with each other by addressing localhost. For example, if a container in a Pod wants to reach another container in the same Pod on port 8080, it can use the address localhost:8080.
Pod Manifest file
apiVersion: v1
kind: Pod
metadata:
name: nginx-pod
labels:
app: nginx
tier: dev
spec:
containers:
- name: nginx-container
image: nginx
We can define Kubernetes objects in 2 formats: yaml (yet another markup language) and json (javaScript object notation).
ApiVersion
It defines the version of the Kubernetes API you’re using to create this object.
- v1: It means that the Kubernetes object is part of first stable release of the Kubernetes API. So it consists of core objects such as Pods, ReplicationController and Service.
Kind
- It defines the type of object being created.
Each configuration file has three parts
✴ Metadata
Data that helps uniquely identify the object, including a name string, UID, and optional namespace.
✴ Spec
The precise format of the object spec is different for every Kubernetes object, and contains nested fields specific to that object.
✴ Status
It’s going to be automatically generated and edit by kubernetes so the way it works is that kubernetes will always compare what is the desired status and what is the actual status of that component and if it do not match then kubernetes knows there’s something to be fixed there, so it’s gonna try to fix it.
💥Commands
Kubernetes command-line tool (kubectl), allows you to run commands against Kubernetes clusters. Here are some kubectl commands.
kubectl get : This command is used to list all the object in a cluster, and is a great way to get an overview of what's running where.
kubectl describe pod : This command gives you detailed information about a specific pod, including its status, IP address, and more.
kubectl logs : This command lets you view the logs for a specific pod, which can be really helpful for debugging purposes.
kubectl exec -it : This command lets you execute a command in a specific pod, which can be really handy for troubleshooting.
kubectl scale --replicas=: This command is used to scale up or down a deployment, and is a great way to manage your resources.
💥Installation
👉 Click on Link for Kubernetes installation according to your requirements.
Above blog is submitted under 'Blogathon Contest 2022' conducted by Devtron
Check out their Github repo ⭐ Github.